幻觉生成模型研究提升人工智能的可靠性
发布时间:2024-06-21 11:21:51来源:
牛津大学的研究人员在确保生成人工智能(AI)产生的信息的稳健性和可靠性方面取得了重大进展。
在《自然》杂志上发表的一项新研究中,他们展示了一种新方法来检测大型语言模型(LLM)何时可能“产生幻觉”(即发明听起来合理但却是虚构的事实)。
这一进步可能为在法律或医学问答等“粗心大意的错误”代价高昂的场合部署法学硕士学位开辟新的途径。
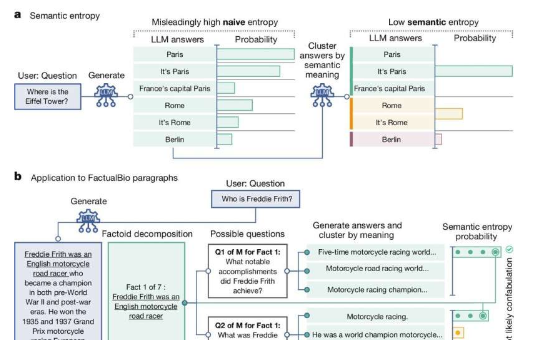
研究人员重点研究了幻觉,即法学硕士每次被问到问题时都会给出不同的答案——即使措辞相同——这种现象被称为虚构。
牛津大学计算机科学系的这项研究的作者塞巴斯蒂安·法夸尔博士说:“法学硕士很擅长用许多不同的方式来表达同一件事,这使得我们很难分辨他们什么时候对答案有把握,什么时候只是在编造一些东西。”
“使用以前的方法,无法区分模型不确定要说什么和不确定如何说。但我们的新方法克服了这个问题。”
为此,研究团队开发了一种以统计学为基础的方法,使用基于多个输出之间的变化量(以熵为衡量标准)来估计不确定性的方法。
他们的方法在意义层面而非词序层面计算不确定性,也就是说,它可以发现 LLM 何时不确定答案的实际意义,而不仅仅是措辞。为此,LLM 产生的概率(表示每个单词在句子中出现的可能性)被转化为意义概率。
经过针对六个开源 LLM(包括 GPT-4 和 LLaMA 2)的测试,新方法被证明比所有以前的方法更能准确地发现问题何时可能被错误回答。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。